
Standard benchmarks play a pivotal role in the field of software engineering, serving as a foundational element for ensuring quality and efficiency. The Transaction Processing Performance Council (TPC) benchmarks, in particular, have established a high standard across the database sector. These benchmarks are designed to simulate real-world database usage, offering a platform for comparing various database products in a manner that is fair, fundamental, and reproducible.
However, it is important to acknowledge that not all code is created equal. In reality, a significant portion of software is far from being optimally written. There are numerous reasons for this. Often, developers are constrained by tight deadlines, lack of interest or passion for the project, or simply the pressure to make things work within a limited timeframe. As a result, a lot of the software available today is not finely tuned or optimized. To mitigate this issue, considerable efforts have been made to enhance compilers and the internal mechanics of CPUs, aiming to compensate for less-than-optimal coding practices.
At Green Coding Solutions we have developed a great measurement infrastructure that enables us to measure software reproducible and really see how changes reflect on the impact software has. Now that we can measure code we want to start applying green coding techniques and see how these affect the resource usage. Also a lot of work is currently going on in this space [0][1] but one big problem is that there is no real benchmark of code that can be optimised and that can be measured before and after the changes are applied. I strongly believe that this is a big problem as currently everyone selects their own little piece of code and such there is a) no way to compare results and b) wrong results or conclusions might happen as there is no sound fundament.
So we set out to create a repository with such code. The main aims are:
- The code is non optimal and can be “improved”
- The code is well tested
- Functions run long enough to be measured
- The code run is constant in energy consumption
The aim is also to support a wide breath of problems and languages with not only including trivial problems.
Currently we only include a very limited set of python functions that can be optimised but the idea is to collect loads of examples and actually implement a lot of things that are considered code smells[2].
Find the code under:
https://github.com/green-coding-solutions/code-benchmark
We have included a Green Metrics Tool usage_scenario.yml file so you can benchmark the code with the GMT. Currently the problems are all CPU bound but we will extend this to also have some memory or IO bound problems that can be optimised.
Feel free to contribute and extend the problem space. PRs welcome!
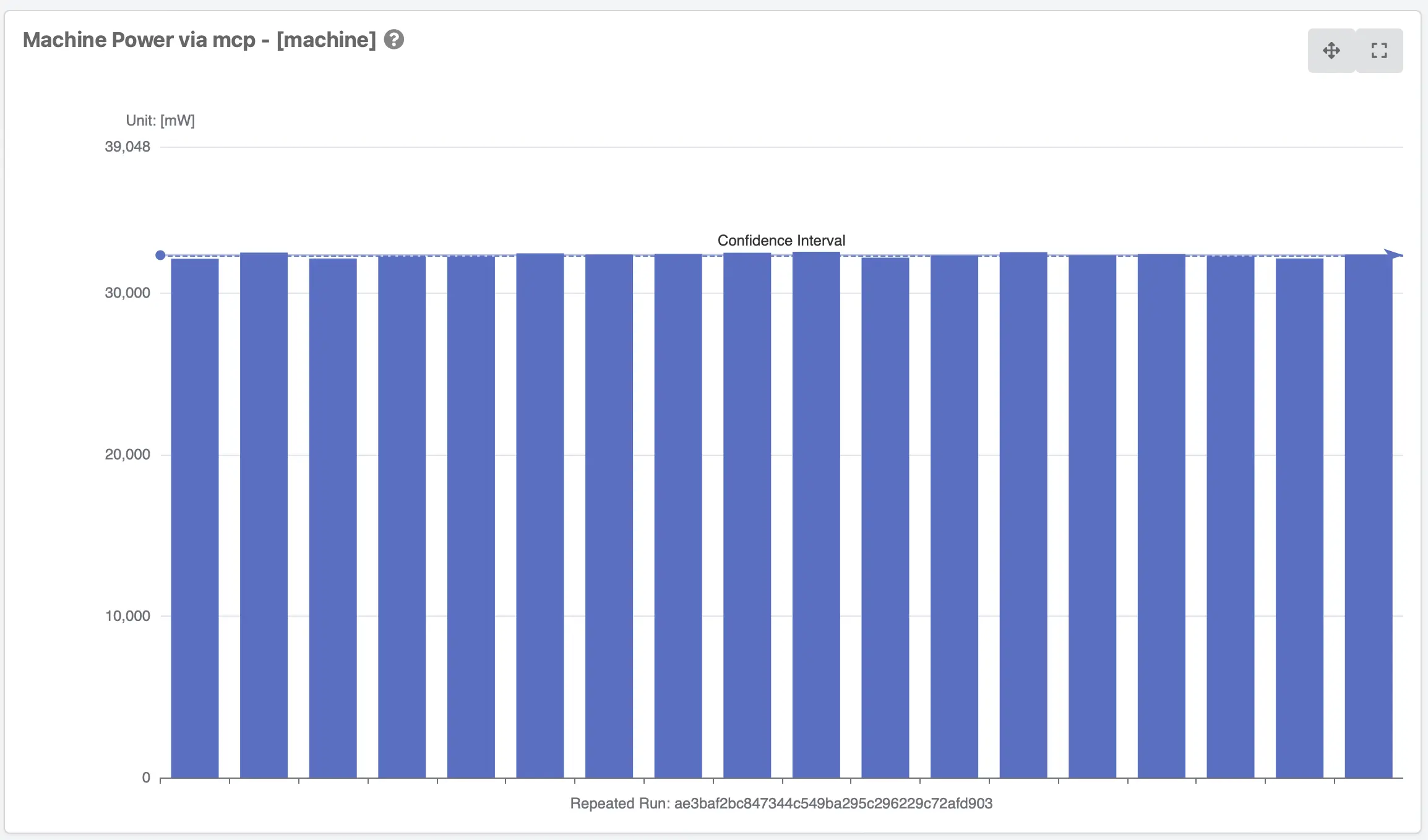
Reproducibility
In order to validate that some modification really changed the value the initial benchmark needs to run reportable and should minimize variations between runs. You can find the data here
[0] Influence of Static Code Analysis on Energy Consumption of Software
[1] https://www.meetup.com/green-software-development-karlsruhe/events/296796570/