| Language | Benchmark | vs. C [CPU Energy] | vs. C [Machine Energy] |
|---|
| Python 3.6 | binary-trees | 60x | 56x |
| Python 3.6 | fannkuch-redux | 66x | 63x |
| Python 3.6 | fasta | 34x | 38x |
| Python 3.6 | TOTAL | 61x | 58x |
Source: Measurements, charts and details
| Language | Benchmark | vs. C [CPU Energy] | vs. C [Machine Energy] |
|---|
| Python 3.9 | binary-trees | 51x | 49x |
| Python 3.9 | fannkuch-redux | 72x | 68x |
| Python 3.9 | fasta | 30x | 33x |
| Python 3.9 | TOTAL | 63x | 61x |
Source: Measurements, charts and details
| Language | Benchmark | vs. C [CPU Energy] | vs. C [Machine Energy] |
|---|
| Python 3.12 | binary-trees | 33x | 33x |
| Python 3.12 | fannkuch-redux | 57x | 54x |
| Python 3.12 | fasta | 28x | 31x |
| Python 3.12 | TOTAL | 50x | 48x |
Source: Measurements, charts and details
| Language | Benchmark | vs. C [CPU Energy] | vs. C [Machine Energy] |
|---|
| PyPy 3.10 | binary-trees | 5x | 7x |
| PyPy 3.10 | fannkuch-redux | 21x | 25x |
| PyPy 3.10 | fasta | 22x | 18x |
| PyPy 3.10 | TOTAL | 18x | 21x |
| Language | Benchmark | vs. C [CPU Energy] | vs. C [Machine Energy] |
|---|
| Mojo | binary-trees | 51x | 48x |
| Mojo | fannkuch-redux | 65x | 62x |
| Mojo | fasta | 32x | 36x |
| Mojo | TOTAL | 58x | 56x |
DISCUSSION
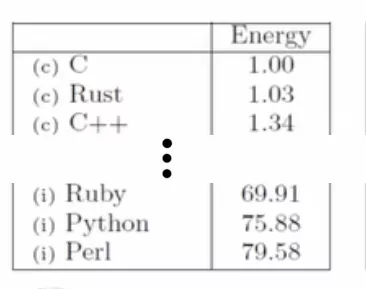
What stands out with these results is that we cannot exactly reproduce the 75x difference between Python and C. Our data only shows a 60x difference.
These are the best python versions in descending order:
| Language | Overhead vs. C [Machine Energy] | | |
|---|
| PyPy 3.10 | 21x | | |
| Python 3.12 | 48x | | |
| Mojo | 56x | | |
| Python 3.6 | 58x | | |
| Python 3.9 | 61x | | |
The reason for that is most likely that we use newer and different hardware. However what should be expected is that we at least have a similar offset for the singular tests,
which is also not the case.
In the original paper the differences for the single tests comparing Python 3.6 with C are:
- binary-trees: 45x (CPU Energy) => 25% less
- fankuch-redux: 59x (CPU Energy) => 11% less
- fasta: 38x (CPU Energy) => 11% more
So not only are the values off, also the tendency swaps direction for the fasta test.
We have no explanation for that at the moment.
For the TOTAL value of all these three tests combined at least there is an uncertainty what the authors here accumulated exactly.
Specifically if it is just the average of the ratios (60+66+34/3) or if it is the sum of the total energies and then the ratio (which is what the Green Metrics Tool does).
In any case, it would not explain the differences in the singular tests, so we did not investiage here any further.
What we can see though is that Python definitely made an increase in efficiency from Python 3.6 to Python 3.12 (with a suprising bump for Python 3.9 :) )
Coming back to our initial research question we can attest that using Python today is around ~18% more efficient. That being sad you are probably at least around 48x times worse than C
on a plain compute job :)
Moving to a different interpreter like PyPy though makes a strong improvment and overall and is more than 50% more efficient than Python 3.12.
Which means it is only around 21x worse than C … in selective cases also down to 7x, which is pretty strong!
Mojo showed no relevant improvements which is mostly due to the fact that it cannot natively enhance Python code at the time of writing.
It will just wrap the Python code and import it as a module and then run it with the native Python interpreter (libpython). See our discussion on their Github